ActivityPub is cool because we finally have an open protocol to post and subscribe and reply to content across apps.
Mastodon is not Twitter. I get why people think of Mastodon as open source or distributed Twitter, but it’s more than that. If you add ActivityPub support to your WordPress site, others can see the comments and reply from Mastodon! I think this will get more obvious as time goes on and apps like Tumblr start to implement ActivityPub support as well.
After 9 years, 2 months, and 23 days, today is my last day at Automattic.
I owe a lot to WordPress, Automattic, VIP, and now WooCommerce. I initially learned PHP as a teenager by reading the WordPress source code and writing WordPress plugins and themes. Building websites was one of the very first things that got me interested in Computer Science.
I still have an email from Andy Skelton dated April 3, 2006. I was having problems with the new sidebar widgets feature and without knowing what else to do, emailed Matt for help. Andy replied with a patch that fixed the problem. I remember wanting to learn how to fix problems like that for myself. I was 15 at the time. A little over 14 years later, I ended up working on the same team as Andy when he switched to VIP Systems.
I applied to be an intern with (at the time) the WordPress.com VIP team after seeing Matt announce it on Twitter.
Sometimes I think about how big of an impact that moment had on my life. It’s hard to imagine how much different the last 10 years would have been for me otherwise.
It’s weird leaving a company after 10 years. I remember Matt telling me that I was the 200th person Automattic had hired. I think there were something like 180 full time employees back then. Now there are over 2,000 Automatticans. As I’ve been reflecting on some of the meetups and projects I’ve worked on over the years, some of those early memories feel like they’re from a different company.
On the other hand, it’s striking how similar the culture still is. We still use P2s (internal blogs) for communication. There’s still a small team of Systems Engineers running most of the infrastructure, including one of the fastest DNS hosts on the internet. One of the biggest changes (other than the number of people) is that most teams switched from IRC to Slack years ago. 🙂
Automattic is made up of tons of smart, fun, kind people who are trying to make the web a better place. I’m so happy to have been a part of it.
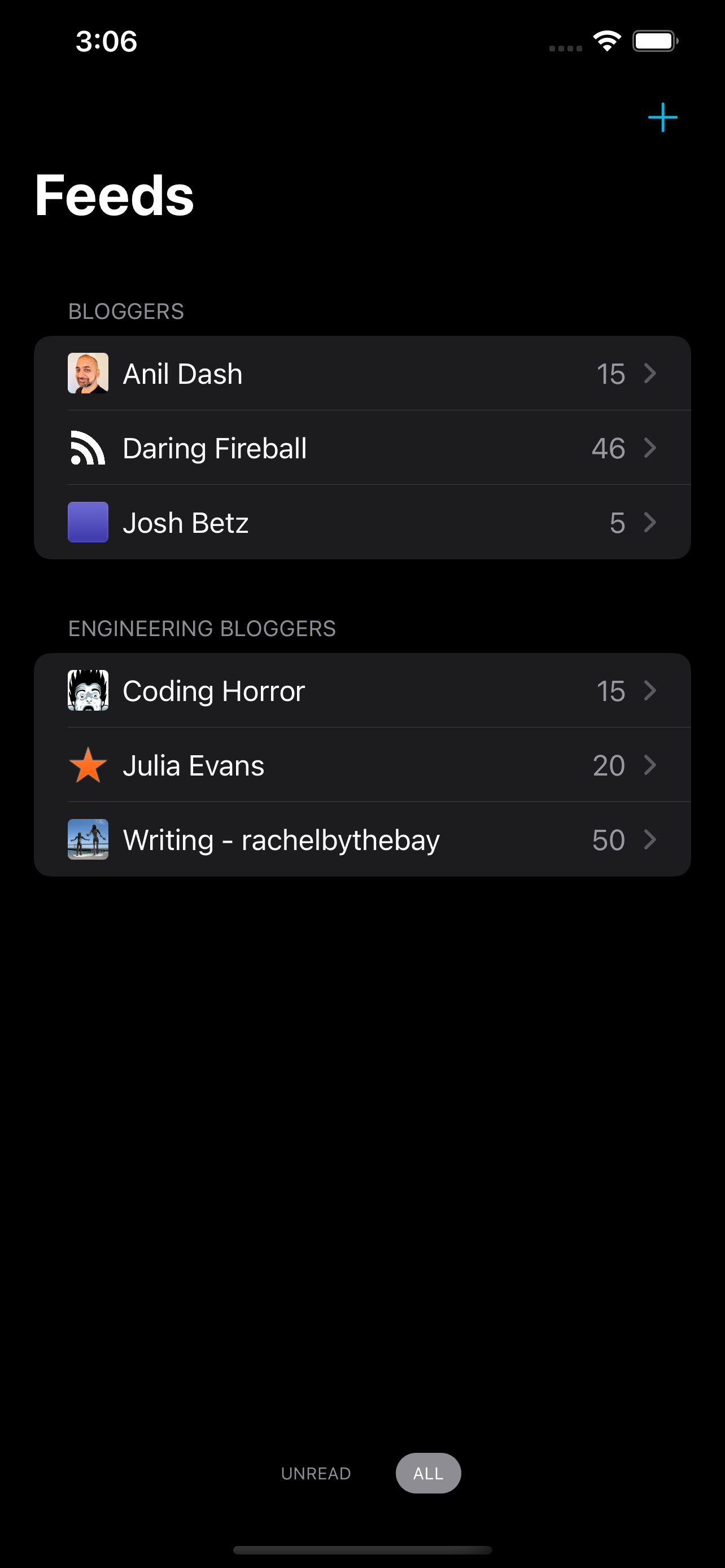
Wire started as a sabbatical project a little over three years ago. I wanted an RSS reader that didn’t require an account and displayed articles in web views instead of the traditional method of styling article content in a “reader” view. People spend a lot of time on their websites and I think reader apps should respect that.
Wire 2.0 is a complete rewrite using SwiftUI and an improved offline caching system. I’ve been using versions of this new app for quite a while, but until iOS 15 it wasn’t possible to build some of the features I wanted with SwiftUI.
Syncing between devices also works much better than before. I love being able to read articles on my phone and iPad and having that state all kept in sync. If you’re signed into your iCloud account, it just works.
If you try it, let me know what you think. And please rate and review the app on the App Store 🙃